|
|
4 minute read
DataOps methodology stands to data management like DevOps stands to software development and is gaining momentum as the most comprehensive response to challenges in Big Data and analytics projects as the wall breaker that makes data owners and data consumers finally collaborate.
Thanks to DataOps, business leaders can make data-driven decisions and drive organizational change unleashing the access to corporate data while, at the same time, staying compliant with data governance policies such as GDPR or CCPA, just to name two.
With the expression “broken data analytics pipeline” we identify a collective set of challenges that most organizations, sooner or later, find on their roadmap to become data-driven. These challenges are responsible for common scenarios whereas, for example, data sources are unavailable to data scientists due to restricted access to data and lack of collaboration. Other challenges, such as the lack of data automation and machine-learning supporting data preparation technologies and data governance policies, force organizations to rely too extensively on human rework and delay the production of new apps and dashboards. These challenges are both technology and operational debts that almost all data-driven organisations face.
Despite leaders’ efforts to address these issues looking for a more data-oriented trajectory for their organizations, the progress toward treating data as a valuable asset remains poor. As many projects and strategies emphasizing data and analytics fail, the percentage of companies identifying themselves as being data-driven has been declining steadily in each of last three years – from 37.1% in 2017 to 32.4% in 2018 to 31.0% in 2019, according to NewVantage Partners’ Big Data and AI Executive Survey 2019.
 DataOps, or data operations, focuses on overcoming these challenges cultivating data management practices to improve the speed and accuracy of analytics, including data access, quality control, data governance, automation and integration. DataOps methodology involves people, processes, tools, and services to bridge the gap between a vast array of enterprise data sources and data consumers with governed pipelines. In a nutshell, DataOps helps rapidly, repeatedly, and reliably deliver error-free data to every authorized user.
DataOps, or data operations, focuses on overcoming these challenges cultivating data management practices to improve the speed and accuracy of analytics, including data access, quality control, data governance, automation and integration. DataOps methodology involves people, processes, tools, and services to bridge the gap between a vast array of enterprise data sources and data consumers with governed pipelines. In a nutshell, DataOps helps rapidly, repeatedly, and reliably deliver error-free data to every authorized user.
To this end, DataOps applies the best practices of Agile development, DevOps and Big Data to all stages of data management operations and analytics.
In a dynamic software development setting, Agile methodology is proven to accelerate time to value with fewer defects than the traditional sequential Waterfall approach. Data management teams are also used to working in environments where requirements are quickly evolving – a situation where DataOps steps in. In a DataOps context, Agile methods enable data management professionals to boost collaboration and deliver new or updated data analytics in short intervals called ‘sprints’. In this way the team can efficiently switch between priorities, promptly respond to changing requirements and receive continuous feedback from data consumers. DataOps ensures that the data management team is not locked into a long delivery cycle, keeping data away from users in silos.
To this end, DataOps applies the best practices of Agile development, DevOps and Big Data to all stages of data management operations and analytics.
Like DevOps, DataOps emerges from the recognition that separating the product (clean and complete data) from the process that delivers it (operations) impedes quality, timeliness and transparency. Focused on the build lifecycle acceleration, DevOps promotes continuous integration and delivery of software by leveraging on-demand IT resources and by automating integration, test and deployment of code. DataOps helps manage continuous flow of data for effective operations on both data lakes and data warehouses, by introducing self-service capabilities to bypass conventional manual and time-consuming methods of data discovery, testing and delivery.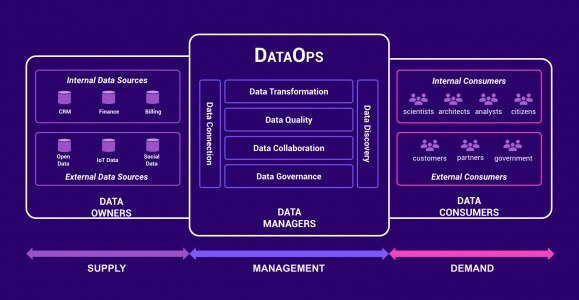
Active metadata is like hot gossip. Here’s why.
Setting DataOps practices helps organizations benefit from ‘data democracy’– which means making data flows easily reach data scientists, analysts and business users in a fast, efficient and secure way. At Fyrefuse, we know the importance of Data Management architectures at every point of the data operations pipeline, so errors are detected and fixed before they reach analytics. We promote a new approach to analytics where data scientists are always equipped with secure sandboxes and vast data availability, so new analytics can be released in rapid increments. We promote DataOps to help organizations democratize their data silos and start leveraging data-driven actionable insights while automating enterprise-wide data governance.
DataOps is not a single product but rather an umbrella term for a set of best practices, cultural norms, and architectural patterns that enable:
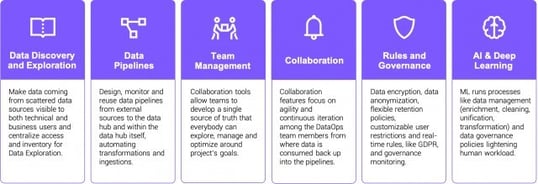
- Data Discovery and Exploration, visualising data from various sources to facilitate enterprise-level Data Exploration Data Pipelines, automating transformation and ingestion to ensure high quality and very low error rates Team Management, providing multi-expert teams with a single source of truth on available data Collaboration, encouraging agility and continuous feedback response across people, technology and environments Rules and Governance, leveraging automation and ML assistance to maintain the highest security, privacy and provenance and retention tracking standards AI & Deep Learning, lightening human work with insights on data management operations and data governance
At its core, DataOps is about optimizing the way an organization manages its data according to the goals it has for that data. If the goal is, for example, reducing a customer’s churn rate, one could embark on a project to build a recommendation engine that surfaces products that are relevant to customers. But that’s only possible if the data science team has access to the data necessary to build and continually feed the model, and collaboration tools as such project will likely include input from the engineering, IT, and business teams as well. DataOps framework allows data owners to share their data, data managers to construct custom governed pipelines and data consumers to get actionable insights from continuously updated and error-free data.
Despite being a relatively new term, DataOps emergence has been and will be in the future years a true breakthrough that impressed a drastic improvement in the way organizations find, deliver and use data in less than a decade. DataOps is gaining mainstream popularity thanks to top analyst firms like Gartner, Eckerson, and Forrester who have all been including this topic in their research. Indeed, Gartner has placed DataOps on the innovation phase of the Hype Cycle for Data Management in 2019.
Surely, DataOps addresses many enterprise data management issues, especially when it comes to handling data lakes or enterprise-level datasets at scale. At Fyrefuse, DataOps experts make sure our clients achieve the fast and seamless improvement of the product delivery and deployment along with full-scale interoperability between data sources and data consumers.
.png?height=200&name=Untitled%20presentation%20(2).png)
.webp?height=200&name=img-01%20(2).webp)







