|
|
4 minute read
Modern data questions often involve stakeholders with heterogeneous backgrounds, spanning from data scientist to a line-of-business representative or even a marketing specialist. All of them bring their own individual expertise to the collaboration, and Big data projects can easily fall short of clear expectations and communication. This article will reveal a few tips for how to boost collaboration to help organisations become truly data driven.
Nowadays, thanks to accessible cloud deployment options, inexpensive hardware and flexible cluster management, the ability to collect and store data scales, yet the ability to process and consume seems to be lagging behind. Leveraging Big data analytics in an organisation inevitably means having the right people on the job as part of a data team working together to derive insights from vast amounts of data the business collects. Although the following tips may require a bit of extra set up effort, they are crucial for organisations to ‘make data happen’.
1. Outlining roles and responsibilities and making them transparent for everyone
Collaboration is the key to success, but team diversity could create too much conflict or inefficiency. Outlining the roles and responsibilities of each team member is a crucial step to assembling an agile data team. Simple on the surface, it may not be an easy task given the scope of data projects. According to a recent research by Gartner, there is a substantial increase in the amount of business roles that support data management activities.
While the number of roles may vary, the chief categories will mostly include Data Owners, Data Managers and Data Consumers. Though these roles form the backbone of productive data management, the skill sets associated with each one are different enough to make collaboration a significant challenge. For example, while a Data Owner is likely to be a database administrator, a Data Manager may be a data architect, a Data Consumer could be any of data scientist, business, user, analyst, etc. All roles are important: ignore any of them, and the team will likely not be able to accomplish as much as they would otherwise.
The lines between these roles often become blurred. In some situations, a person from one role can assume the responsibilities of another, like when a data manager becomes a data scientist. Though this can happen, it’s important to differentiate these roles. Expecting any of these people to handle multiple roles or understand all of them is surely asking too much. Defining each role makes it easier for data teams to focus on collaboration and know who to refer to.
2. Develop a culture of data sharing
The “old” centralised way of managing and delivering data is slow and unresponsive, limiting data-derived value. The new way of work means organisations must embrace DataOps, decentralise and empower company-wide self-service data exploration and analytics. A safe and efficient way to treat data as a common asset is maintaining a structured and business-user friendly metadata catalog that everyone in an organisation can navigate.
Data democratisation and self-service technologies enable DataOps, but they work best within a corporate culture that encourages experimentation as the path to insight. The innovative, data-driven organisation is made up of curious employees seeking new answers to make the most of available data. A data-discovery experimentation mindset should not be data scientists’ inherent attribute, but also line-of-business stakeholders need to adopt a ‘what-if’ and ‘what can be done’ outlook. Defining common business glossary and setting rules for an abstracted semantic layer would ensure everyone “speaks the same language” and agrees upon what the data (and metadata) is and is not.
3. Automate the processes of Data Requests, Quality and Governance
While the previous tip pushes towards agility and collaboration, at the same time we must not ignore the need to keep data quality and governance under tight control. One way to do so is to formalise the process of Data requests.
Requesting data organically evolved into a long and tedious procedure taking weeks or even months. Though there is no quick fix to this problem, improving communication between all data roles and providing digital tools for requesting data should be a best practice to follow.
The problem of many organisations is that data is hidden behind multiple intermediaries and rounds of requests and the access is limited in fortunate cases to data scientists and analysts. Empowering every party involved with the opportunity to request data on a routine basis will unlock the full potential of a company’s data assets. Setting SLA-level delivery expectations for internal data customers, whether they are analysts, developers or business users will resolve the infamous data consumption bottleneck.
The problem of many organisations is that data is hidden behind multiple intermediaries and rounds of requests and the access is limited in fortunate cases to data scientists and analysts. Empowering every party involved with the opportunity to request data on a routine basis will unlock the full potential of a company’s data assets. Setting SLA-level delivery expectations for internal data customers, whether they are analysts, developers or business users will resolve the infamous data consumption bottleneck.
It is also important to understand what is the business value behind the data request to find the right questions for the data to answer. Sometimes a request for a specific metric might miss the bigger question that data can solve. For example, a consumer might say “I need data on churn” but what they mean is "we need to find a way to minimise churn". If they were to build a chart that simply listed churn over time, they’d miss all the other data points that correlate with churn such as customer satisfaction data and many more. It’s the data team’s job to connect data from different sources and maximise business value.
By improving data requests, it is way easier to make sure that the output data fits with the data consumer needs and that all of the permissions and roles are satisfied.
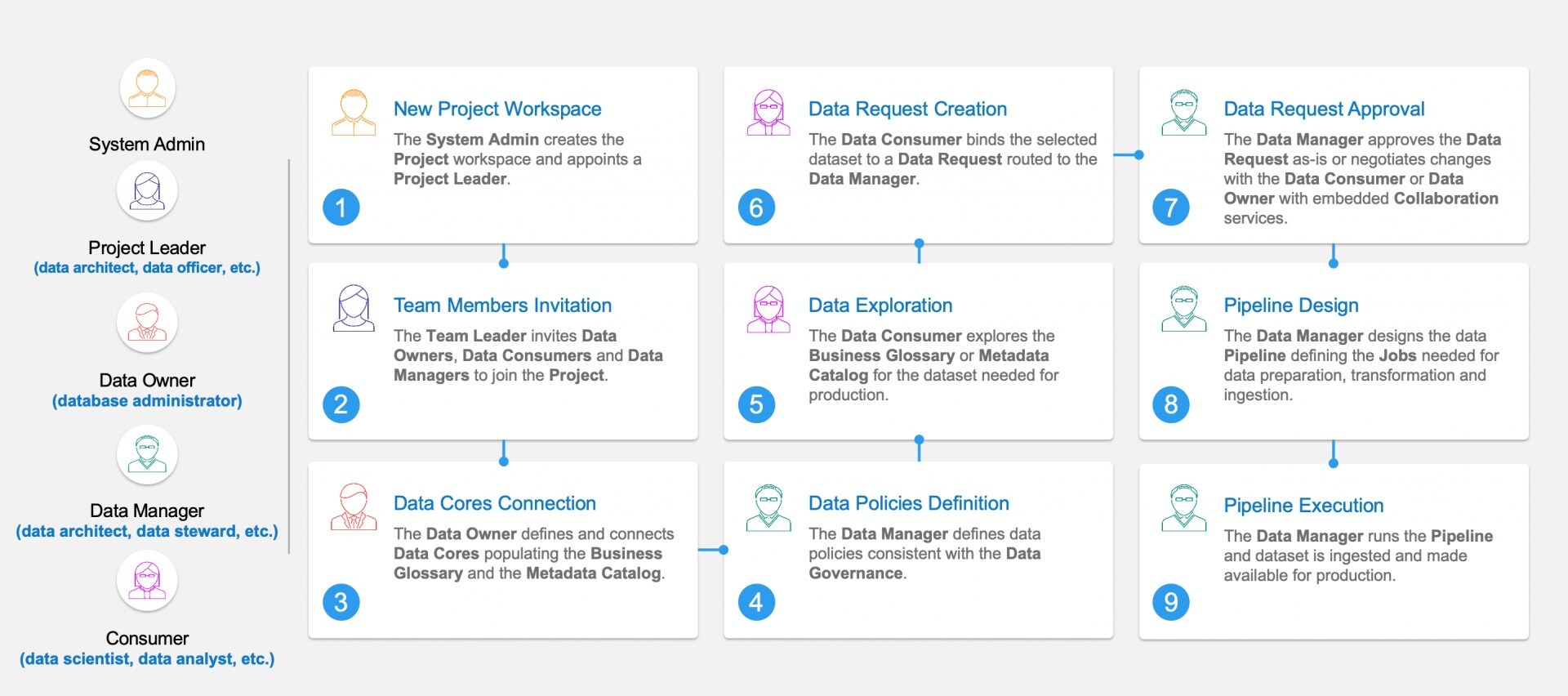
The workflow above provides an example of collaboration in the DataOps setting. As we can see from this workflow, defining roles and responsibilities, sharing common data landscape and automating data requests and governance are the cornerstones of efficient data management where decisions are rooted in data.
If your organisation is ready to fast track analytics and adopt all three tips and much more with a unique tool, we do have a solution. Fyrefuse is an end-to-end DataOps platform that automates and connects stakeholders, tools and policies to improve data life-cycle in a Big data organisation. Main features include Data Discovery and Exploration, Data Pipelines, Team Management, Collaboration, Rules and Governance. The platform is built using best-of-breed open source technologies such as Scala, Akka and Lagom and it is powered by a user-friendly portal that leverages Python, Django and Angular 8. Get in touch with us to know more or schedule a demo.
.png?height=200&name=Untitled%20presentation%20(2).png)
.webp?height=200&name=img-01%20(2).webp)







